[1人1P] 3. DB 설계
![[1人1P] 3. DB 설계](/content/images/size/w1200/2026/03/IMG_8220.jpg)
DB 설계란?
서비스를 효율적이고 경제적으로 운영하기 위해서는 체계적인 DB 설계가 필수적이다. 본 포스트에서는 1인 개발자로서 백엔드 개발 전 서비스의 기틀을 다질 수 있는 DB 설계에 대해서 다루고 한다.
DBMS
DB(DataBase)는 컴퓨터상에서 데이터들을 저장하기 위한 서비스이다. 그리고 이를 운영하기 위한 소프트웨어가 DBMS(DataBase Management System)이라 생각하면 쉽다. DBMS에는 종류와 형태가 다양하지만, 이번 프로젝트에서는 PostgreSQL을 사용하는 것을 기반으로 하고 진행할 것이다. PostgreSQL은 최근들어 많은 스타트업 개발자들에게 각광받고 있는 DBMS이다. PostgreSQL은 관계형 데이터 처리에 강력하며, JSON/JSONB 같은 반정형 데이터도 유연하게 다룰 수 있다는 장점이 있다.
소규모의 서비스의 경우에는 MySQL이나 다른 NoSQL 서비스를 사용할 수도 있었겠지만, 서비스 확장성을 고려한 설계를 하기 위해 PostgreSQL로 진행할 것이다.
DB 요구사항
직접적으로 DB를 설계하는 과정에 들어가기 전에는 서비스의 요구사항을 정리하는 과정이 필요하다. 어떤 기능을 구현해야 하는지, 어떤 API를 만들 것인지에 대한 내용을 사전에 정리해두어야 그에 적합한 DB 스키마를 설계할 수 있기 때문이다.
나는 이번 프로젝트에 대한 요구사항을 다음과 같이 정리해보았다.
1. 사용자 관련
- 사용자 정보를 저장할 수 있어야 한다.
- 각 사용자는 자신의 할 일, 회고, 점수, 작업 기록을 개별적으로 관리할 수 있어야 한다.
- 사용자별로 데이터가 구분되어야 한다.
2. Todo 관련
- 사용자는 할 일을 등록, 수정, 삭제할 수 있어야 한다.
- 할 일은 날짜별로 관리될 수 있어야 한다.
- 할 일의 완료 여부, 지연 여부 등의 상태를 저장할 수 있어야 한다.
- 할 일을 여러 개의 컬렉션 또는 그룹으로 나누어 관리할 수 있어야 한다.
3. Review / Delay 관련
- 사용자는 할 일에 대한 복습 또는 리뷰 내용을 기록할 수 있어야 한다.
- 할 일이 지연된 경우, 지연 여부와 관련 내용을 기록할 수 있어야 한다.
- 이를 통해 단순 완료 여부뿐 아니라 학습 및 작업 진행 과정도 함께 관리할 수 있어야 한다.
·
·
·
(생략)이러한 정의서를 바탕으로 DB를 설계하는 것이 불필요한 DB 스키마의 수정을 예방할 수 있고, 보다 효율적이고 정확한 DB 설계를 가능하게 한다.
논리적 DB 설계
흔히 DB를 설계하는 과정에서는 ERD를 작성하게 된다. ERD는 엔터티와 관계를 시각적으로 정리하여 데이터 구조를 파악하는 데 도움을 준다. ERD를 통해 앞서 설명한 DB 설계의 장점을 시각적으로 확인할 수 있다. ERD를 제작하고 표기하는 방법에도 여러가지가 있지만, 대체로 이론적 기반이 많이 필요하기 때문에 이번 프로젝트에서는 단순화된 DB를 설계하기 위해 DrawDB라는 인터넷 툴을 활용하였다.
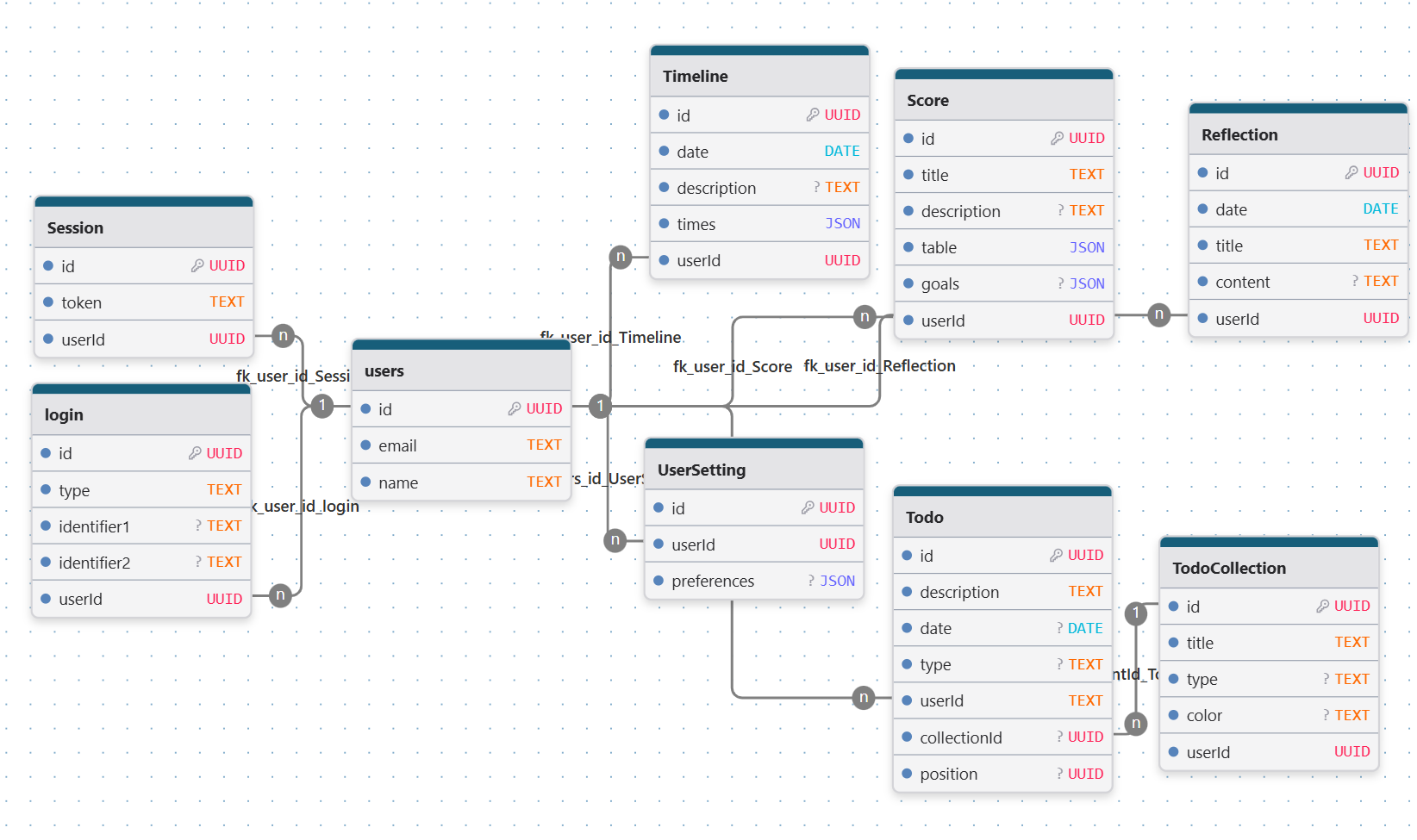
나는 위 사진과 같이 DB를 설계해보았다. DB에 대한 공부량도 부족하고 처음 설계해보는 것이기 때문에 부족할 수 있지만, 내가 생각할 수 있는 범위 내에서 데이터베이스의 관계를 잘 활용해보려 노력하였다.
우선 사용자 정보는 users 릴레이션에 저장된다. 그리고 다른 모든 릴레이션에서 users 릴레이션의 id를 외래키로 참조한다. 이를 통해 사용자 기반의 관계형 DB를 만들 수 있다.
session 릴레이션에서는 사용자 로그인 시 refresh token을 저장해두었다가 access token 만료 시 사용자의 요청을 받고 refresh token 검증 후 access token을 재발급 할 때 사용된다.
login 릴레이션에서는 사용자 로그인에 대한 부분을 저장한다. 구글로 로그인 시에는 구글에서 제공하는 구글 식별자를 받아서 저장하여 OAuth 로그인이 가능하도록 하고, 비밀번호 로그인 시에는 비밀번호를 bcrypt로 해시하여 저장한다.
소셜 로그인의 경우 공급자(provider)와 공급자 측 사용자 식별자(providerUserId)를 저장하여 계정을 연동할 수 있다.
물리적 DB 설계
앞서 설계하였던 ERD를 기반으로 물리적으로 DB를 설계하는 단계이다. ERD를 설계하는 것은 논리적으로 DB의 형태를 구조화하는 단계라면, 이번 단계는 실제 코드와 ORM을 사용하여 DB를 만드는 단계인 것이다.
ORM(Object-Relational Mapping)은 데이터베이스의 테이블을 프로그래밍 언어의 객체로 매핑하여 SQL을 직접 작성하지 않고도 데이터를 조작할 수 있도록 도와주는 기술이다. SQL 쿼리를 ORM이 처리함으로써 SQL 쿼리에 대한 개발자의 부담을 줄여준다. 프로젝트에서 어떤 종류의 ORM을 사용할 것인지 정한 뒤, 해당 ORM의 문법에 맞도록 DB를 만들어야 한다.
나는 이번 프로젝트에서 NestJS(TypeScript)와 PostgreSQL로 백엔드를 제작할 것이기 때문에 NestJS에서 널리 사용되는 PrismaORM을 사용하여 DB를 관리할 것이다.
enum LoginType {
PASSWORD
GOOGLE
}
model User {
id String @id @default(dbgenerated("gen_random_uuid()")) @db.Uuid
email String @unique
name String
profile String?
permission Int @default(1)
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
deletedAt DateTime?
logins Login[]
sessions Session[]
timelines Timeline[]
scores Score[]
reflections Reflection[]
todos Todo[]
todoCollections TodoCollection[]
userSetting UserSetting?
@@map("users")
}model Todo {
id String @id @default(dbgenerated("gen_random_uuid()")) @db.Uuid
description String
date DateTime? @db.Date
type String?
position Float
completed Boolean @default(false)
userId String @db.Uuid
collectionId String? @db.Uuid
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
deletedAt DateTime?
user User @relation(fields: [userId], references: [id], onDelete: Cascade)
collection TodoCollection? @relation(fields: [collectionId], references: [id], onDelete: Cascade)
@@index([userId])
@@index([collectionId])
@@map("todos")
}
model TodoCollection {
id String @id @default(dbgenerated("gen_random_uuid()")) @db.Uuid
title String
type String?
userId String @db.Uuid
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
deletedAt DateTime?
user User @relation(fields: [userId], references: [id], onDelete: Cascade)
todos Todo[]
@@index([userId])
@@map("todo_collections")
}PrismaORM 문법으로 만든 DB 스키마 코드의 일부를 발췌한 것이다. ERD를 통해 시각적으로 형상화했던 DB의 구조를 코드로 옮긴 것이라 생각하면 쉽다.
id String @id @default(dbgenerated("gen_random_uuid()")) @db.Uuid
description String
date DateTime? @db.Date간단히 이 세 속성만 설명하자면, id 속성은 String 타입의 데이터를 가지며 사용자 입력이 없을 시에는 랜덤으로 UUID를 생성하여 저장한다는 의미이다. 즉, ORM에서는 String 타입으로 구현되지만 DB에는 UUID 타입으로 저장되는 것이다.
description 속성은 String 타입의 데이터를 가지고, date 속성은 DateTime 타입의 데이터를 가지면서 nullable 속성이다. nullable 속성은 db에 데이터가 추가될 때 필수적으로 존재하지 않아도 되는 속성이라는 것이다.
마무리
위와 같은 DB 설계 과정을 거치면 효율적이고 경제적인 DB 생성을 마칠 수 있다. 다음은 실제 테이블로 생성된 DB의 모습이다.

테이블의 속성들이 알맞게 설정되어있고, 유저 또한 한 명이 추가되어있는 것을 볼 수 있다.
다음 포스트에서는 이렇게 생성된 DB를 바탕으로 실제 백엔드를 제작하는 과정을 작성해볼 예정이다.
![[1人1P] 5. 프론트엔드 개발 & 배포](/content/images/size/w720/2026/06/-------------2026-06-16-153412.png)
![[1人1P] 4-3. 백엔드 개발 (기능 구현)](/content/images/size/w720/2026/06/-------------2026-06-16-151724.png)
![[1人1P] 4-2. 백엔드 개발 (API 명세 작성)](/content/images/size/w720/2026/06/-------------2026-06-05-214751.png)